建筑生长的视频怎么做?用即梦就能轻松制作出,简单又好玩
建筑生长的视频怎么做?
这么一问,大家可能有点懵了,建筑还能生长?
那么,我先放张效果动图上来给大家看看,其实就是建筑物从地面拔地而起,类似植物一样生成长起来的视频效果。

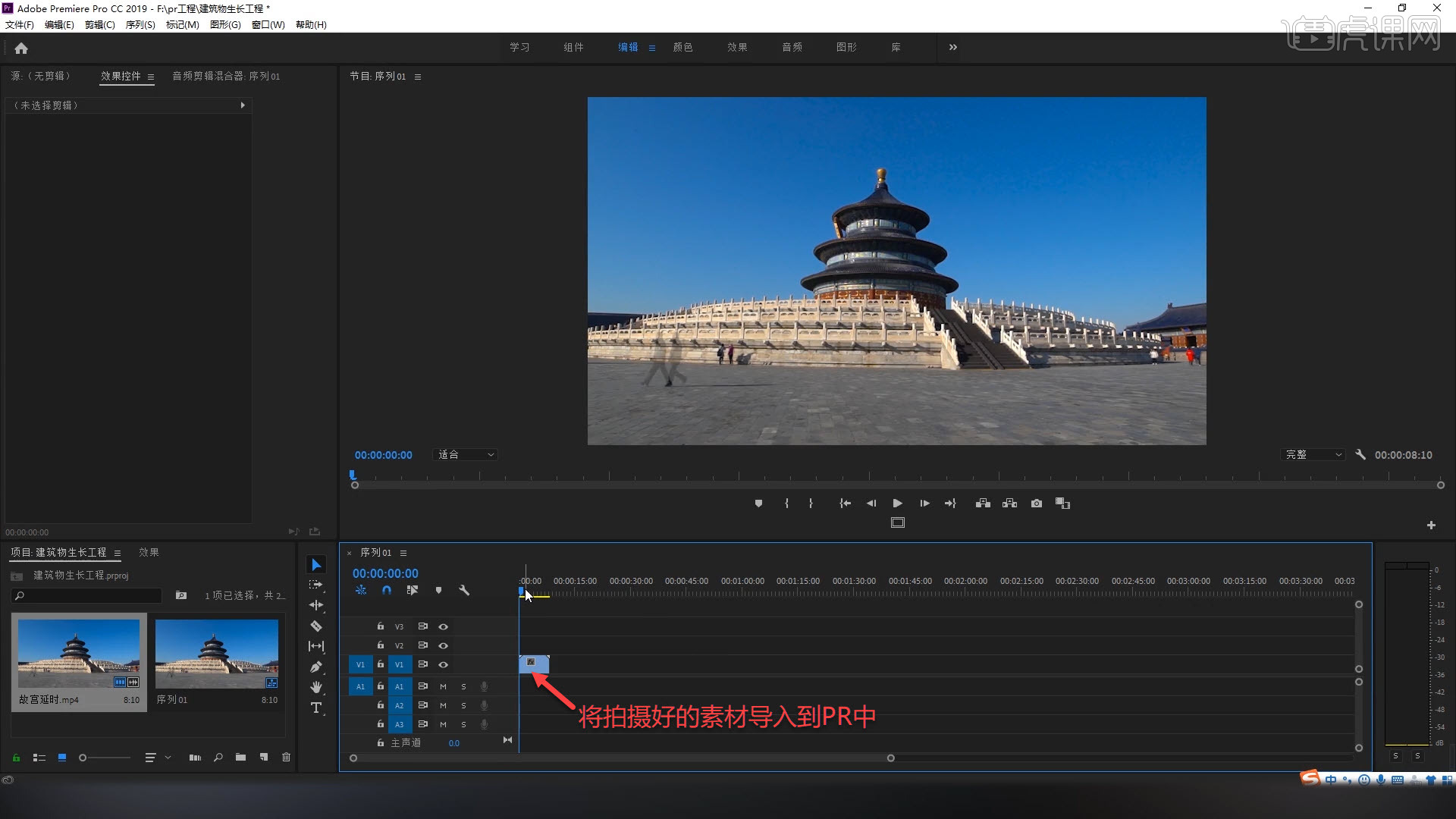
这样的视频效果怎样做的呢?
这里我们要用到的工具是【即梦AI】,
打开【即梦AI】,
把下面是一张带有主体建筑物的原图,

把这张原图导入到【即梦AI】里,

给它一个P图指令:把图片中的主体建筑物去掉。
如果效果不太好的话,
可以试试以下的P图指令:
把图片中的塔去掉;把图片中主体建筑去掉,留下底层的平台;只把图片中的主体建筑去掉,其它的细节与构图不变;把塔去掉后的样子如下,

另外如果对一句话P图指令出来的效果不满意的话,
可以用手动编辑图片功能,
这个功能在放大图片后的右上角,
点【编辑图片】,

进入到编辑图片界面后,点右下角的【消除】功能

在需要消除的区域涂抹一下,

然后点【箭头】发送,这样就能把图片中的主体建筑物消除掉了。

另外,如果觉得用即梦P图不好用或者不顺手的话,
可以用豆包来处理,
打开【豆包】,上传原图,
输入P图指令:把图片中的主体建筑物去掉。
剩下的就交给豆包了。

个人感觉,用豆包比即梦更简单利索一些。
图片处理好后,接下来我们回到【即梦AI】,
我们要利用即梦AI的首尾帧功能来制作建筑生长的视频效果。
打开【即梦AI】,选择【视频生成】

先把处理过的图片导入,

然后再点另一个【+】号,把原图也导进来,
在输入框里输入动态视频的描述词:图中的建筑主体由下往上搭建,逐渐的过渡到第二张图片中的效果

视频模型选择【视频3.0】,比例是原图比例,
最后点击【生成】按钮即可。
下面是最终的动图效果,当然,大家还需要把生成的视频导入到剪映里面,配上适合的音乐才能完事。

文章到此结束。感谢阅读,感谢关注,感谢点赞,感谢推荐,感谢收藏。
无需NeRF高斯点后处理,视频秒变游戏模型成现实
V2M4团队 投稿
量子位 | 公众号 QbitAI
只需一段视频,就可以直接生成可用 的4D网格动画?!
来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。这意味着无需NeRF/高斯点后处理,可直接导入游戏/图形引擎。
该方法构建了一个系统化的多阶段流程,涵盖相机轨迹恢复、外观优化、拓扑统一、纹理合成等关键步骤,让视频“秒变模型”,大幅提升动画与游戏内容的生成效率与可用性。
论文已被ICCV 2025正式接收。

结果显示,其生成的外观和结构高度还原,平均每帧仅需约60秒处理,比现有方法显著提速;而且还支持「长视频」,在300帧时长的视频上依然表现优异
视频生成4D动画模型有多难?
从一段视频生成连续动画网格资产,一直是视觉计算长期未解的问题:传统动画制作需依赖多摄像头、动捕设备、人工建模等高成本手段。隐式方法如NeRF虽能复现外观,却难以直接输出拓扑一致的显式网格。
而近期的原生3D生成模型能够重建出高质量的3D网格,但常常存在姿态错位、拓扑不一致、纹理闪烁等问题。
在该工作中,V2M4首次展示了利用原生3D生成模型,从单目视频生成可用4D网格动画资产的可能性,并展现了其视觉效果与实用性。
V2M4提出一套系统化的五阶段方法,直接从单目视频构建可编辑的4D网格动画资产。该方法以“生成高质量显式网格+拓扑一致+纹理统一”为目标,从结构、外观、拓扑和时序角度逐步优化模型,输出可直接用于图形/游戏引擎的4D动画文件。

相机轨迹恢复与网格重定位
由于原生3D生成模型输出的每帧网格常处于标准坐标系中心并且朝向固定,因此直接采用原生3D模型生成视频帧对应的3D网格会导致真实的平移和旋转信息的丢失,进而使得动画无法还原物体在视频中的真实运动。
为解决该问题,V2M4设计了三阶段相机估计策略,通过重建每帧视频的相机视角,进而将“相机运动”转化为“网格运动”。
候选相机采样+DreamSim评分:在物体周围均匀采样多个视角,渲染并与真实帧对比,挑选相似度最高的相机姿态。DUSt3R点云辅助估计:引入几何基础模型DUSt3R,通过预测点云来推算出更稳定的相机位姿,再与采样结果融合。粒子群优化+梯度下降精调:用PSO算法避免局部最优,再以渲染出的掩模差异为优化目标,通过gradient descent精细调整最终相机参数。最终,将估计得到的相机轨迹反向应用于每一帧3D网格,从而将网格从标准姿态中“还原”回视频中的真实空间位置,实现真实的动态建模。

外观一致性优化:条件嵌入微调
即使完成空间对齐,初始生成的网格外观往往与输入视频存在一定外观差异。为此,V2M4借鉴图像编辑中的null text optimization策略,对生成网络的条件嵌入进行微调,以DreamSim、LPIPS、MSE等指标衡量渲染结果与参考视频帧的相似度,从而优化嵌入向量,使生成的网格外观更加贴合原视频,实现更高质量的外观一致性。

拓扑对齐与结构一致性:帧间对齐+局部约束
由于现有3D生成模型在每帧输出中存在随机性,相邻帧的网格往往在拓扑结构上存在差异,例如顶点数量、边的连接方式或面片组织均不一致。这类结构差异会严重阻碍动画的连续性与可编辑性。为解决此问题,V2M4引入了逐帧配准与拓扑统一机制:以首帧网格为标准形态(rest pose),通过全局刚体变换和局部形变优化,逐步将其拓扑结构传递给所有后续帧。在配准过程中,该方法结合Chamfer距离、可微渲染损失与ARAP刚性形变约束,实现对整体姿态和局部结构的精准调整。最终,所有帧网格不仅在形状上保持高度连续性,更在拓扑层面实现完全一致,从而为后续纹理生成与时间插值奠定稳定基础。
跨帧纹理一致性优化:共享UV提图,消除闪烁与断裂
为了确保动画过程中外观的一致性,V2M4为所有帧构建了一张共享的全局纹理贴图,避免了逐帧独立纹理所带来的色彩跳变与贴图断裂问题。由于前述拓扑统一后,各帧网格的结构保持一致,该方法以第一帧网格的UV展开作为所有帧的纹理基准,并基于多视角渲染优化贴图细节。为提升与原视频匹配的局部质量,该方法引入视角加权机制,对应视频帧的相机视图被赋予更高权重。最终,实现外观一致、帧间平滑的动画体验。
网格插帧与4D动画导出:轻量封装,一键部署
为了提升动画的时间连续性与软件适配性,V2M4对生成的网格序列进行时间插帧与结构封装。具体而言,该方法对关键帧网格的顶点位置进行线性插值,生成时序上更平滑的动画序列,并进一步将其表示为:单个静态网格,加上一组随时间变化的顶点位移张量。最终结果被导出为符合GLTF标准的动画文件,包含统一拓扑结构、共享纹理贴图与顶点时序变形,可直接导入Blender等主流图形与游戏引擎进行编辑与复用。由此,该方法实现了从视频到4D网格动画资产的完整转换路径,具备可视化、可编辑与实际应用兼容性。
效果验证与评估
为系统评估 V2M4 的性能,该工作在比以往更具挑战性的视频数据上开展实验,结合定量与定性对比,验证其在重建质量、运行效率与泛化能力上的全面优势。
定量对比:性能全面领先
该方法基于CLIP、LPIPS、FVD和DreamSim等主流指标,从语义一致性、视觉细节与时序流畅性等维度,评估输入视频与重建网格渲染之间的匹配度,更贴近真实用户感知。
与DreamMesh4D和Naive TRELLIS等方法相比,V2M4在Simple(轻微动作)及Complex(复杂动作)两个数据集上各项指标均实现领先。同时,依托高效的插帧与纹理共享机制,平均每帧仅需约60秒即可完成重建,大幅优于现有方法。

视觉对比:结构更清晰、外观更真实
在视觉效果方面,V2M4生成的网格在渲染细节、法线结构与跨帧一致性上表现更出色,不仅还原度高、拓扑完整,更能稳定生成连续、流畅的动画,展现出优异的实用性与泛化能力。
论文链接:https://arxiv.org/abs/2503.09631
项目主页:https://windvchen.github.io/V2M4
相关问答
OpenAI发布视频生成模型Sora,效果如何-ZOL问答
两个月前去参加NeurIPS会议的时候,我还知道有一些做计算机视觉和生物信息学的小伙伴们不太看好用AI生成模型来做视频。我们当时热烈讨论过这个问题,但是大家普...
怎么把3d模型做成视频动画?
要将3D模型制作成视频动画,您可以按照以下步骤进行操作:1.选择合适的3D建模软件:首先,您需要选择一款适合您需求的3D建模软件。常见的3D建模软件包括Blende...
大专数字媒体专业,想学Blender做MMD模型,有什么建议?-ZOL问答
在民间常见的方向有改模、制作场景以及K帧,这三个领域相对而言入门门槛较低,但上限却非常高,且随着难度逐步递增。改模可以非常简单,例如拿到别人的素体后随意...
给视频制作阴影用模型制作的人物,在视频中怎么做出动态的阴影。难度大也没关系,求给个解决方案?
找一块纯色(蓝色或者绿色无纺布不能反光)背景打上灯光进行拍摄后用后期软件抠像剪辑合成很多软件都可以抠像EDPRAEVG会声会影等等都可以做到找一块纯色(蓝色...
短视频是否有版权问题_法律问答—华律网
[回答]专业分析:短视频是有版权纠纷的。【法律依据】《著作权法》第三条规定,本法所称的作品,包括以下列形式创作的文学、艺术和自然科学、社会科学、工程...
请问一下,关于这样的画质画风的3D动画来讲;单单自己用C4D来建模、渲染出一个一分钟的视频,有多难?
经验相关:曾使用ae,朋友用过c4d,学生首先说一下我的经验。ae一个模板,三维变换不少。用我们学校电脑(配置:i7、1080ti、64GB内存),渲染了3个小时左右。...
大家了解新壹科技的视频大模型都有哪些功能么?-ZOL问答
新壹科技大模型是新壹科技在视频领域的重要突破,是国内首个聚焦视频AIGC领域的语言大模型,以视频生成为核心的AIGC模型,拥有从脚本生成、素材匹配、素材生产...
开源AI项目MegActor,基于视频生成可动人像动画的技术细节-Z...
MegActor的技术原理是先用视频分解出一堆关键帧再通过神经网络捕捉人脸的动作和...这个开源项目的核心是借助预训练模型处理输入视频提取面部肌肉运动数据以及头...
视频模型是什么意思?
视频模型是一种计算机技术,它使用机器学习和人工智能算法来分析和理解视频内容。视频模型可以识别和分类视频中的对象,预测视频中可能发生的事件,以及生成新的...
视频模型概念?
视频模型是指用于处理视频任务的深度学习模型。视频任务包括视频分类、目标检测、行为识别、视频生成等。视频模型的设计与传统的图像模型有所不同,因为视频数...




